See Project Design Discussion for background information.
Knowing which resources of a project to load into memory and when.
Assume that a project requires a set of resources {R1, R2, R3}. In the new design, this can be modeled using the internal attribute resource owned by the Project. This alleviates the project from having a separate data store for holding onto the resources). When the project is loaded into memory, R1 and R2 should be loaded as well but R3 should not (perhaps R1 is the model, R2 is the analysis mesh that the user wishes to use, and R3 is a courser mesh that the user might use in the future). How do we capture this and what mechanism is to be used to perform the action?
1. Project does all the work
This approach requires each derived project to provide an operation to explicitly load the resources into memory. In this example, the designer would create a LoadOperation that would load in R1 and R2 (if they’re set) when the project loads.
2. Base Project provides an initial structure.
In this case, the base project class could provide a simple structure to its internal attribute resource. For example it could have an Attribute Definition called “LoadImmediately” and one called “LoadLater”. A derived project could then add a set of ResourceItems to either of these Definitions and the base project load operation would load all resources listed in the former but not those in the latter. In the above example, R1 and R2 would be captured by ResourceItems under the “LoadImmediately” Attribute and R3 would be a ResourceItem under the “LoadLater” Attribute.
3. Extend Resource Item and its Definition
This approach delegates this responsibility to the ResourceItem and ResourceItemDefinition classes. The ResourceItemDefinition class could have a new property called LoadRequirements with values {LoadImmediately, LoadOnDemand}. An operation could then be created that would walk the attribute resource and load those resources marked with LoadImmediately. In addition, the ResourceItem would also have a boolean property called LoadImmediately that returns true its definition has LoadRequirements = LoadImmediately or if it is marked to be loaded explicitly. The idea for this is to capture the case where the user has loaded the resource into memory explicitly and wants the workflow to remember to load the resource the next time the project in loaded into memory.
In the case of the above example, the ReferenceItemDefinitions for R1 and R2 would have LoadRequirements = LoadImmediately and R3 would have its set to LoadOnDemand.
Benefits
Approach 1
Simplest to implement.
Approach 2
- Very simple structure that makes it very easy to define new types of projects.
- Base Project can provide a load operation that derived projects could reuse.
Approach 3 (My Current Choice)
- Most flexible and can be used outside of the Project Concept
- Generic Resource Load operation could be created and used both by project and non-project workflows
- Base Project does not enforce any information structure in terms of capturing a project’s resource requirements
Drawbacks
- Approach 1 - Every project will need to implement its own “load” operation
- Approach 2- Initial structure can appear limiting
- Approach 3 - None that I see
Relating Project Resources with Task Resources
Let’s assume we have a project that has a set of resources, how can a Task in the Project’s workflow refer to these resources? Once again there are several options:
- The Task uses a ResourceItem that is manually set to the correct resource (either by hand or through an operation). In this case it’s up to the project logic to get this right.
- Use Properties or LinkRoles - in this approach, the Task ResourceItem would be constrained to hold only specific resources which could be tested when determining if the user is allowed to enter that Task. Note that the operation to change the Property/Link Association would not be contained in the Task itself. Meaning that the user would need to leave the Task and enter the one that provides the operation. Note that this would allow the Project to represent a resource as LoadOnDemand while the Task could have it marked as LoadImmediately.
- Use something like an ItemVariant to directly refer to the item in the Project
Projects and the Resource Manager
Lastly I wanted to bring up the issue of how Projects and their Resources work with respects to the Resource Manager. Lets assume we have the following:
- Project 1 (P1) requires resource (R1)
- Project 2 (P2) requires Resources (R1 and R2)
- The user loads in P2 which means R1 and R2 should be accessible in the Resource Manager.
- The user then loads in P1 which doesn’t require anything to be loaded since R1 is already loaded via P2.
- Now the user unloads P2. R2 should be unloaded as well though R1 is still needed.
- Finally the user unloads P1 which should also result in R1 from being unloaded.
Currently the Resource Manager holds a shared pointer to the resource when it is loaded which means without any modification to the code, resources loaded in via Projects would not get removed when the Project is removed.
Here are a couple options:
Project Resources are held by the Project and not the Resource Manager
This would solve the above problem but at the cost of introducing a bigger problem. Namely Projects would need to provide the same search functionality the Resource Manager provides.
Resource Manager has the ability to hold a Resource using either shared or weak pointers
If there was a way to indicate that a resource should be added to the Resource Manager using either shared or weak pointers then the above example would work as described assuming that P1 and P2 Resources indicated the Resource Manager to hold them using weak pointers.

This would also address the following modification of the above example:
4a. The user directly loads in R1
In Step 4a, R1 would be found to be in the ResourceManager as a weak pointer. Since the resource load operation would then add it to ResourceManager as a shared pointer as well.
Since the ResourceManager uses a multi-index array, the simplest way of possibly supporting this would be to have the ResourceManager maintain two arrays - one using shared pointers and one using weak pointers. The same resource could exist in both depending on the circumstances.
Its the Project Manager Job
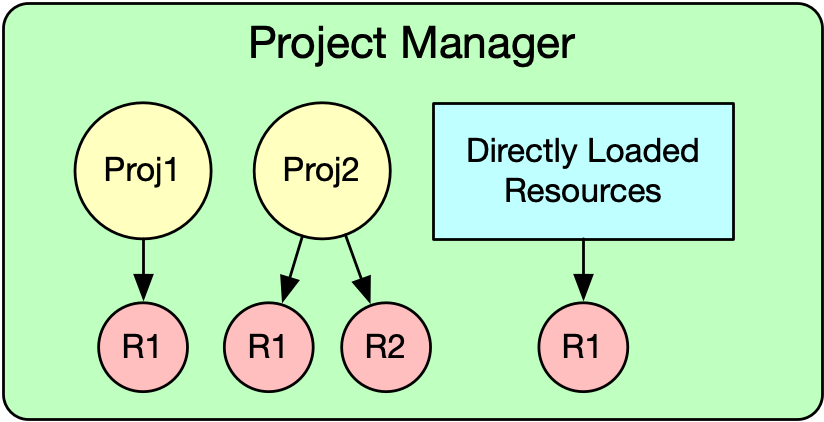
This is sort of the dual of the above approach. The Project Manager could keep track of all Projects in the system (which would be its main job). When a Project is being unloaded, the Project Manager would grab the Project’s list of loaded resources and remove those Resources that don’t exist in either another Project or has been directly added to the Resource Manager.