The task system in SMTK was developed to a point but not integrated with (1) SMTK workflows or (2) SMTK’s GUI components. We are now moving forward with these aspects of the design.
The merge request for the first part of this work is cmb/smtk!2853.
Task definitions and state
One of the first things we need to do is integrate tasks into workflow templates; while we previously provided serialization to/from JSON for tasks, we did not use that serialization anywhere. After some discussion, we will be making the single smtk::task::Manager instance (previously held in smtk::common::Managers as application state) into a per-project object (i.e., each smtk::project::Project will own a task manager and serialize it as part of the resource).
This change requires a different signature for smtk::task::Task constructors; previously, the constructor required only a smtk::common::Managers::Ptr, but since no task manager is held inside the managers container, it must be passed in explicitly. (The smtk::task::Manager owns a smtk::task::Instances object used to construct the proper subclass of task given a JSON configuration object.)
Operation hints
For the most part, users determine when to switch the active task and mark a task complete (when completable). However, operations may sometimes need to do this. We now provide a hint mechanism that operations can use to indicate the active task should change. This is used by the smtk::project::Read to restore the previously-active task when loading a project. Use the free function smtk::operation::addActivateTaskHint() in your operations where it makes sense.
Next steps
Our next steps include a task panel that shows tasks as nodes in a graph. We will follow the design of ParaView’s node-editor plugin.
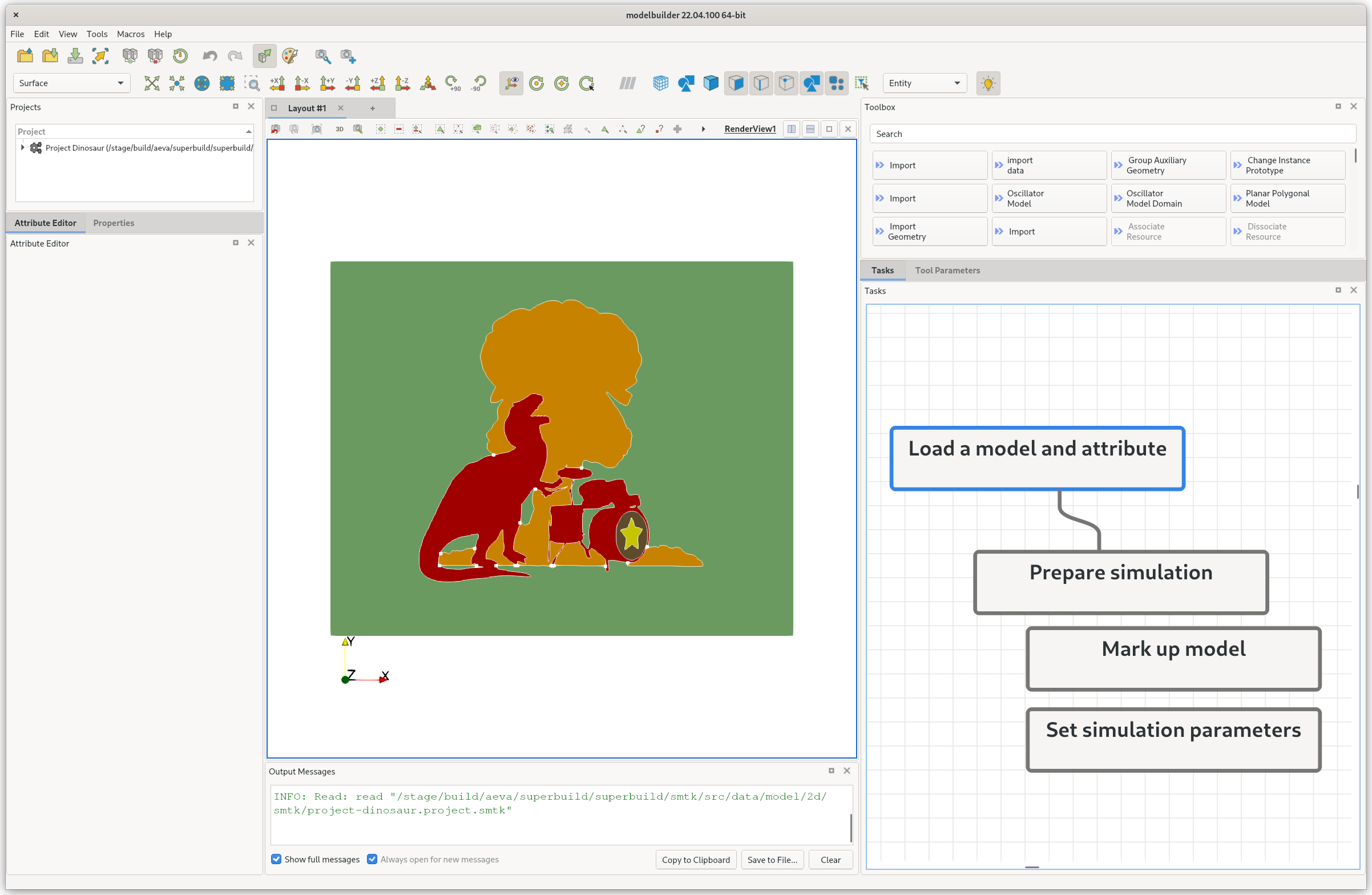
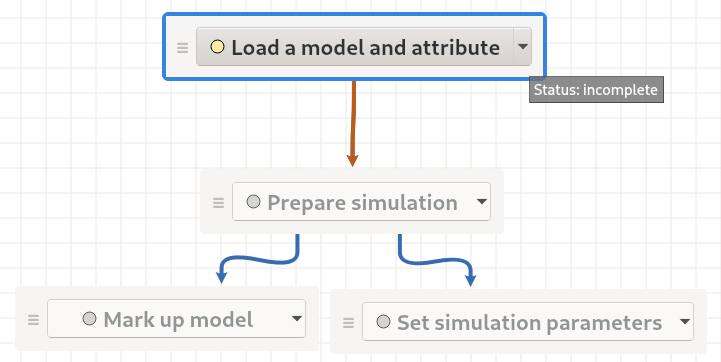
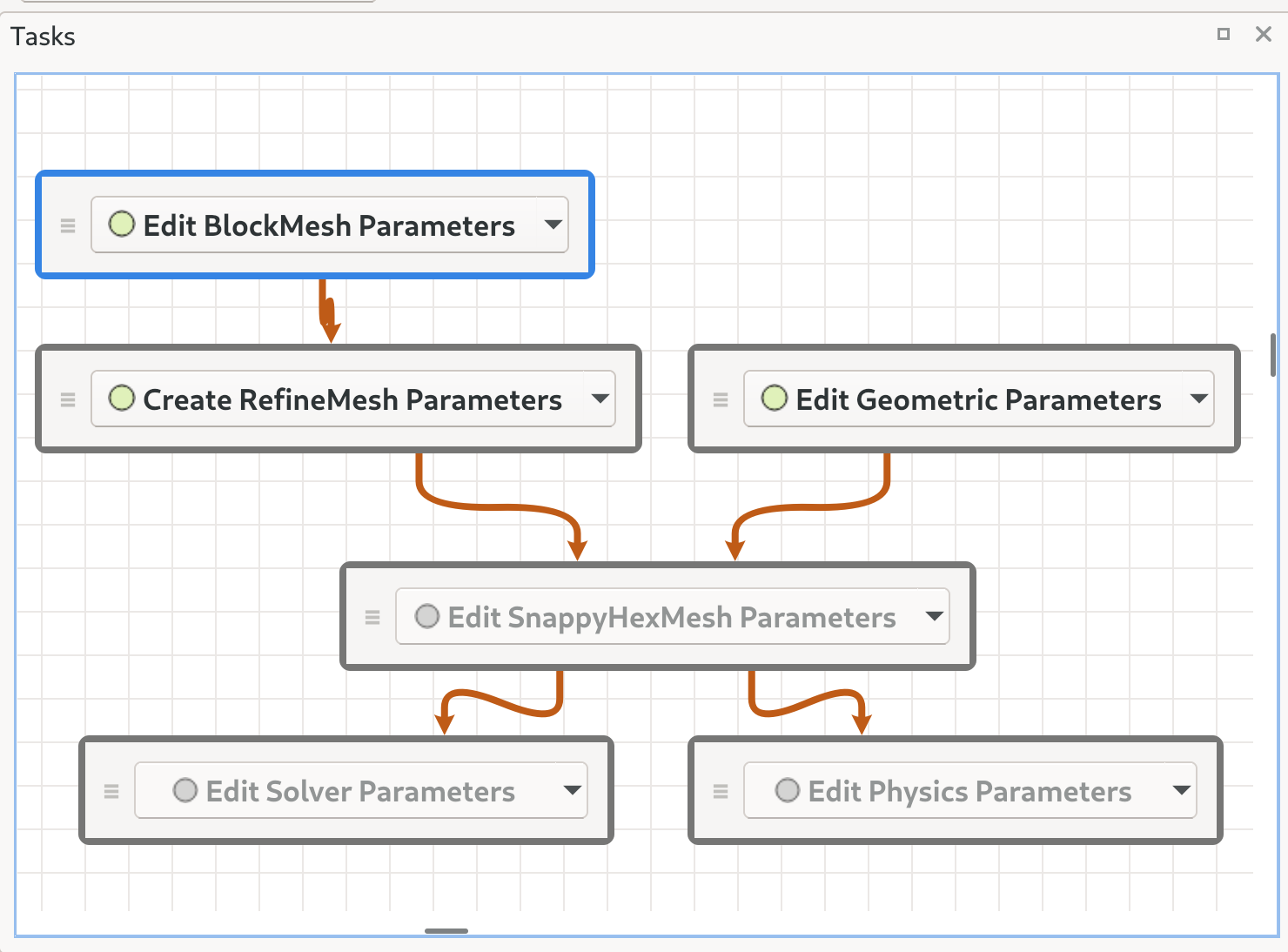
The task panel is at the bottom right of the window and shows 4 task nodes loaded from JSON. There are two toplevel tasks (“Load a model and attribute” and “Prepare simulation”). The second top-level task is a group composed of two subtasks (“Mark up model” and “Set simulation parameters”). The JSON is from the TestTaskGroup test.
Work left to do:
Adding dependency and task-adaptor arcs.
Rendering the active task highlighted.
Indicating the state of each task in the “headline”
Providing users with a way to mark completable tasks as completed (or to “undo” completion).
Render children of group tasks either inside or below their group node, optionally hiding them.
There’s still a lot left to do. Here are some suggestions if people want to work on things related to tasks:
@aron.helser Add reactions (especially setting the active view in the attribute editor) when switching active tasks. Hints for implementing:
Add a styles() method to smtk::task::Manager that returns a JSON object like the example here.
Have the attribute editor panel observe the project manager. When a project is available, have it observe the “active” task on project’s task-manager (see smtk::task::Active::Observers).
When the active task changes, examine the new task’s styles and, if any has an attribute-editor entry, parse that to discover a view name.
The placement of tasks in the task-panel exists only in the Qt layer (each qtTaskNode has a position and is held by the qtTaskScene, in turn held by a qtTaskEditor, in turn held by a pqSMTKTaskPanel). Either we need to move node placement to be part of the smtk::task::Task instance or we need an API with no Qt dependencies to query where nodes are placed in a view. Hints for implementing:
The most expedient solution is simply to add ivars to smtk::task::Task and have qtTaskNode set these each time its layout is changed. Then, smtk/task/json/jsonTask.cxx could include the nodal locations in its own serialization (and deserialize as needed).
Beyond that, the automatic layout that currently occurs when a new project becomes active in the task panel would need to be omitted if nodal locations already exist.
Provide some UI for GatherResources that lets users select from among a project’s resources. Hints for implementing:
Create a new qtGatherResources which inherits qtBaseView.
Register the class with the smtk::view::Manager’s viewWidgetFactory.
Extend qtTaskNode to create a view widget for its “contents” and display it inside the m_controls groupBox (this group box is declared in smtk/extension/qt/task/TaskNode.ui).
This should probably be done after the “Add reactions…” item above since the name of the view configuration for a task node should be part of the task’s style.
Fix a bug that prevents task adaptors from running properly (UUIDs of gathered resources are not communicated to other tasks).
Handle groups of tasks more gracefully. (Choose a layout strategy.)
Streamline interactions with task-nodes for usability (e.g., click or double-click task title button to activate without using a pop-up menu; click a task status “completable” swatch to mark completed). Implementation hints:
Decide on a set of improved interactions. Suggestions include
Clicking on the task title should make it active if possible.
Clicking on the task status swatch should mark it completed/completable if it was completable/completed to begin with. (Other states should have no effect.)
When a task becomes active, if it has a node-view style, the m_controls widget should be shown. When a task is no longer active, its m_controls widget should be hidden (i.e., always auto-expand the active task and auto-collapse inactive ones). This does not prevent users from re-expanding nodes later.
Hovering over a task should display a tool-tip with the task’s status followed by its brief description.
A task should have some affordance to show a complete description to users.
Decide whether to stick with Qt widgets embedded in a QGraphicsItem or to subclass a QGraphicsItem that draws the title, state-swatch, drag-handle, and context-menu button. The latter seems like more maintenance but with more intuitive interaction.
Implement resource schemas (i.e., renaming the attribute resource’s template and templateVersion methods to schema and schemaVersion respectively, then moving them up to smtk::resource::Resource). By making resource schemas a “thing,” we can put task definitions in objects that are progenitors to resources.
The “Remaining Work” section in the post above would get us to a point where projects with pre-existing tasks (i.e., a static set of tasks) wil be usable.
After that there is work in several remaining areas to have a more feature-complete task system. The sections below cover the areas; work could be done in parallel.
Dynamic (user-editable) tasks
The goal here is for users to be able to create new tasks (or even workflows) on the fly. The issue is that workflow designers typically want to constrain what tasks users can create to some pre-configured (or at least partially configured) set.
Creating tasks
The preferred user interface is to have a “toolbox” of tasks (similar to the operation toolbox) that can be dragged+dropped onto the task panel.
Options
We could store a “palette” of partially-configured tasks somewhere in the project (as strings that get deserialized by the task manager at the user’s request). This would effectively be prototypal inheritance.
We could store a “palette” of partially-configured tasks in a “project definition” or “project schema” file. It is unclear where this would live but the advantage it provides over (1) above is that upgrading schema would be simpler.
Operations might create tasks as they run. In this case, (a) these observers must have their invocation moved to the GUI thread or (b) either the base Operation class or each subclass’s ::operateInternal() method would need to postpone triggering observers until the operation completes. (The workflow observers allow this; the task/adaptor instance observers do not yet.)
Some combination of the above.
Issues
When creating a task, users may need to change the title so they can differentiate between tasks of the same type. How can we accomplish this?
How much configuration should be expected of users? Just renaming the task and adding adaptors/dependencies? Or do workflow designers need to indicate some subset of a task’s configurable parameters that users may edit?
Creating dependencies
The preferred user interface is to have the task panel UI provide a mode for editing adaptors and dependencies; in this mode, clicking and dragging between tasks results in a popup to choose a dependency or task-adaptor and provide configuration information.
More task classes
Several additional types of tasks would be useful
Operation task
Purpose – fill out an attribute holding operation parameters and either run the operation (perhaps multiple times before completion) or once upon completion.
Configuration
the name of an operation as well as any parameters to the operation that should be (a) preset or (b) hidden.
a mode flag indicating whether the operation should be run once when the user marks the task complete (autorun) or multiple times before the user marks the task complete (manual).
State
The task is unavailable if the operation manager cannot construct an instance of the operation.
The task is incomplete if (a) the mode is autorun and the parameters are invalid or (b) the mode is manual and the operation has not been successfully. Note that in autorun mode, an unsuccessful result might be used to automatically mark the task incomplete.
The task is completable in manual mode if the operation has run successfully and in autorun mode if the parameter attribute is valid.
Issues
The autorun mode could cause issues if the result operation is long-running since the user could make a dependent task active and then have it become unavailable if the operation fails. A potential solution is to override the UI so that the “mark complete” button does not change the task state but instead runs the operation and examines the result before marking the task complete.
Job monitor task
Purpose – provide users with feedback on job status (job ID, logs, or even co-processing visualization) while accepting input from the user to cancel the job should the need arise.
Configuration
The ID of a job to monitor or a script to run which returns such an ID.
A script to run to cancel or restart the job.
A pipe to read for job log data.
A function run when the job is completed or canceled.
State
The task is irrelevant if no job ID is available.
The task is incomplete if the job has not completed.
The task is completable once the job completes successfully.
Issues
Job queuing systems are widely varied and we do not have an abstraction for interacting with them. It might be wise before implementing this task to create an abstraction with a simple API (queue a job, update a job’s status (called by the queuing system upon completion), cancel a job, fetch job log information, fetch/move/analyze job artifacts).
Should job information (esp. completed jobs) be kept in the project? Or is it per-user state? If the latter, how should this task be serialized so that the project file can be used if transmitted to a different user?
Select persistent objects task
Purpose – Have the user choose persistent objects from one or more resources/projects in one or more roles.
Configuration
The set of available objects from which a user much make a choice, specified as
A set of resources, roles, and filters and/or
A set of named resource or resource+component UUIDs.
A completability flag specifying what is required for completion
number – the number of available components that must be selected
a function that validates the user’s selection
An empty-state flag specifying whether the task should be irrelevant or unavailable when no objects are configured.
State
The task is either irrelevant or unavailable if the set of available objects is empty (depending on the empty-state flag).
The task is incomplete when the completability criterion is unmet
Otherwise the task is completable.
Issues
If a “validator” function is specified for determining completability, how should it be serialized? Do we require a functor object with from_json/to_json methods rather than a simple lamba?
Attribute association task
Purpose – Force a set of objects to be associated to attributes of a given type.
Configuration
An attribute definition (or a named set of attribute instances?) that the specified objects below must be associated with.
A set of persistent objects that must be associated with the attributes from above, specified as either
a named set of persistent-object UUIDs
a collection of resource roles, resource types, and component filters that specify some objects.
An empty-state flag specifying whether the task should be irrelevant or unavailable when no objects are configured.
State
The task is always irrelevant if no attribute instances/definitions are configured.
The task is either irrelevant or unavailable if the set of available objects is empty (depending on the empty-state flag).
The task is incomplete until all of the available objects have a valid association.
Issues
This could also be addressed by adding configuration to the FIllOutAttributes task.
What happens when prerequisites prevent a named object from being associated to a named attribute type/instance? The user is stuck, but what feedback can we provide?
More style reactions
The “Remaining work” section in the post above mentions two reactions that we need immediately (setting a view in the attribute-editor panel and setting a view in a task’s task-panel node). But there are other reactions that would be useful
Setting the visibility of components/resources. (Example: when editing boundary conditions, turn on the visibility of side sets and turn off the visibility of material blocks). This might be a fixed set (i.e., a resource type and component filter) or we might have the reaction understand how to inspect a particular task’s state to fetch relevant objects.
Add a color-by mode to the SMTK representation for rendering components according to their associated attributes (of a particular type) and switch to this mode when performing associations (currently FillOutAttributes, but also see above).
Hide/show/raise any of SMTK’s (and/or ParaView’s?) panels when the active task changes.
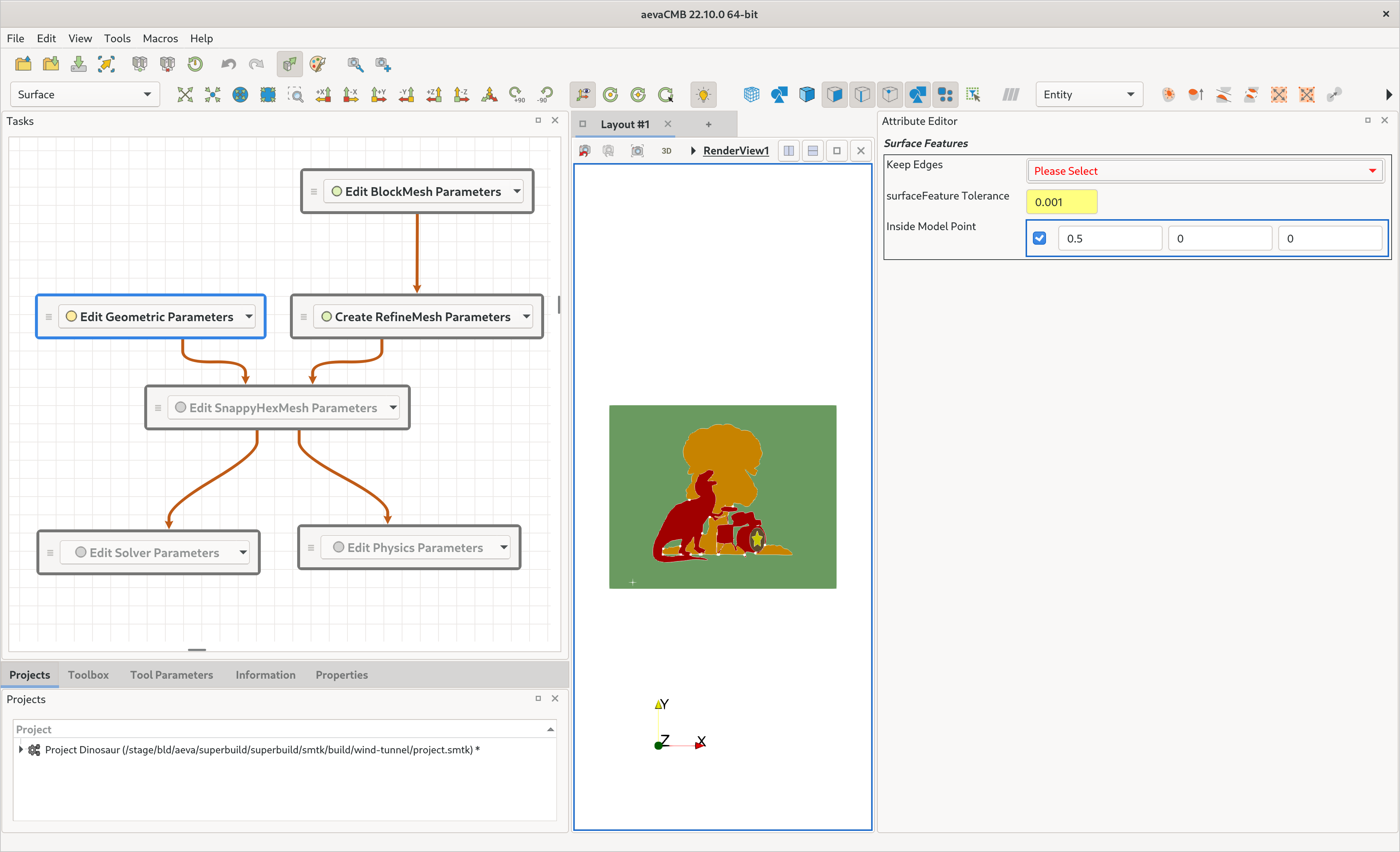
Unzip this archive (a silly example project that contains hand-written tasks) somewhere on your machine.
Run modelbuilder and open the wind-tunnel/project.smtk file included in the archive above.
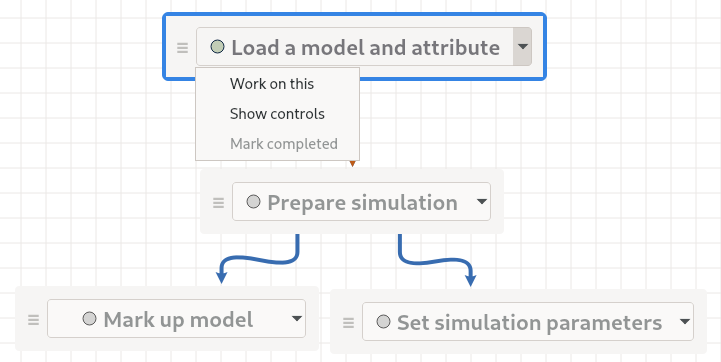
Click on the drop-down menu in each node of the task-panel and select Work on this, then watch the Attribute Editor panel as it shows you parameters related to that task.
Our plan is to merge the branch above in the next few days.
Recent changes
FillOutAttributes task states are now properly computed when the project file already lists resources and attributes to validate (instead of requiring the task to turn on the auto-configure.
All tasks in the example data include proper configuration for the wind tunnel.
SMTK MR 2870 adds an “operation task” named SubmitOperation that guides users to submit an operation (or multiple operations).
Here’s an example showing the SubmitOperation task configured to run the polygon-session’s Delete operation with different “run styles”:
In the video above, you can see that there are three SubmitOperation tasks named “Delete On Completion”, “Delete Iteratively,” and “Delete Once”, corresponding to the 3 ways that operations can be handled by SubmitOperation. These are discussed in detail below.
You can build and run the branch with this hand-edited project, similar to the last post but with the operation tasks as shown in the video.
On Completion
In this variant, the operation’s “Apply” button is not shown. Once the operation is configured properly (by choosing a face to delete), the task state changes from Incomplete to Completable. Marking the task as Completed will run the operation and, on success, remove the operation from the parameter editor. If the operation fails, the task state changes back to Incomplete or Completable so users can retry.
Once
In this variant, the task marks itself as “Complete” once the user has successfully run the operation once (via the “Apply” button). The task is Incomplete until the operation is run. The task will then automatically mark itself Completed when the operation runs successfully. (A failed operation result has no effect.)
Iteratively
This run style allows users to run the operation as many times as needed. The task is Incomplete until the operation has run successfully at least once – at which point it becomes Completable. Note that as soon as a user edits parameters, the task is Incomplete until it is run again.