Problem statement
SMTK’s descriptive phrase view provides a tree that shows resources and/or components in a hierarchy. The top-level entries are generally specified as a filter to select persistent objects from a resource manager. The children of these entries (and all sub-entries) are computed by a subphrase generator class. SMTK has a default subphrase generator that handles model, mesh, and attribute resources. However, graph-resource components are presented as a flat list – which is undesirable. The problem is that
- a graph resource need not be a hierarchy; arcs can create cycles which may confuse users.
- graph resources may have multiple arc types, leaving it unclear which arcs should be used to define the child-phrases of a given component. Listing all components related by any outgoing arc could result in significant clutter and confusion.
We need some mechanism to specify how to use arcs to identify the children of a phrase’s subject component. There are several issues to consider. To illustrate them, examine the graph below. Let’s say we identify components A, B, and C as subjects for the top-level phrases.
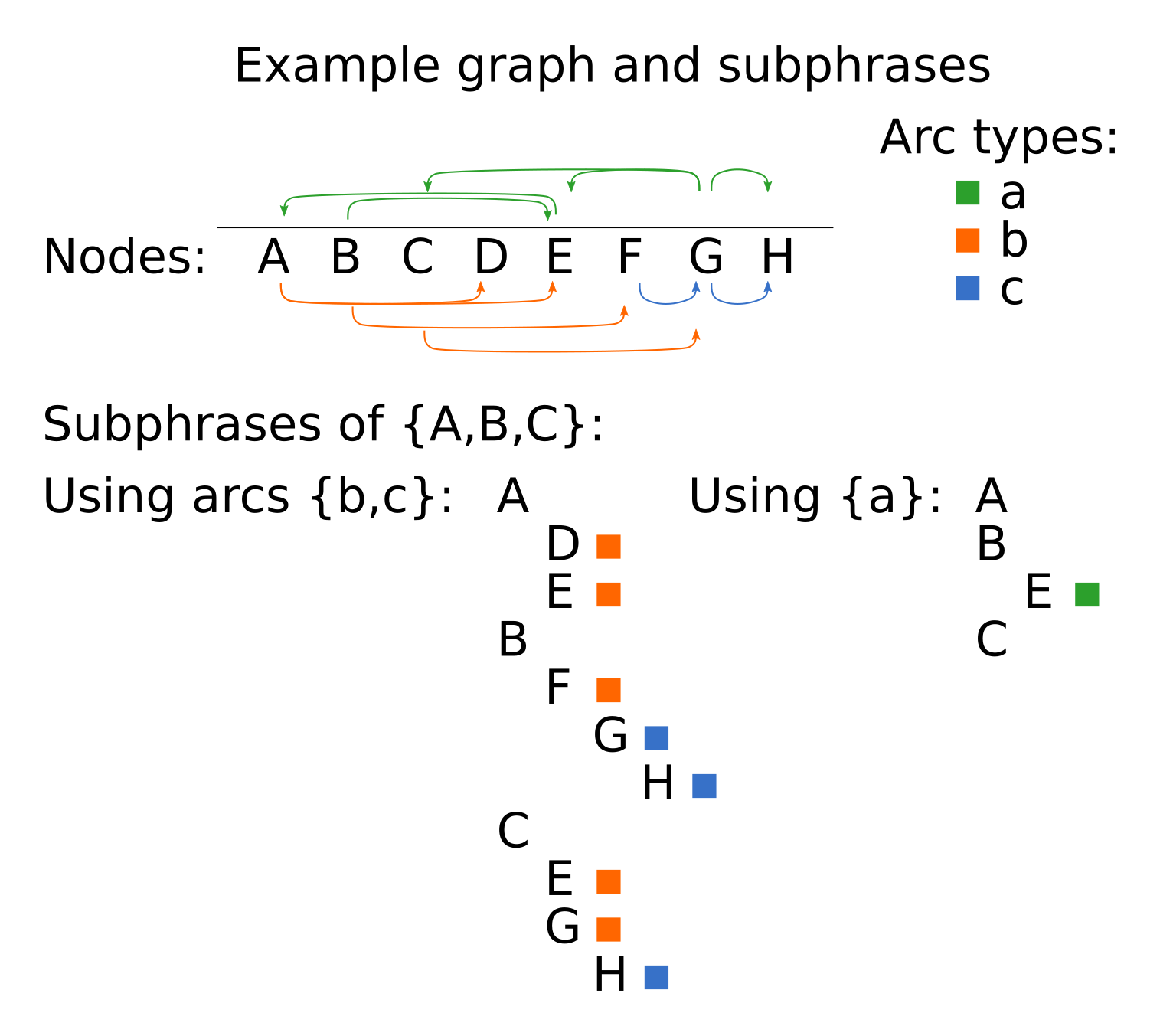
You can see that depending on which arc types we wish to use, the hierarchy may be different. Furthermore, if we used arc types a, b, and c there would be duplicates and cycles (not shown since it would recurse infnitely if expanded fully).
Proposed design
A simple design for a custom subphrase generator would be to template it on a traits object that described the arcs to use, Although it does not support all use cases (especially using different arcs at different depths of the tree), configuration would be minimal:
template<typename SubphraseArcTraits, typename Resource>
class GraphSubphraseGenerator : public smtk::view::SubphraseGenerator
{
// ... SMTK woud provide an implementation.
};
Your plugin would then be required to register a version specialized to your graph resource with the SubphraseGeneratorFactory in your Registrar:
class Registar
{
public:
void registerTo(const smtk::resource::Manager::Ptr& manager)
{
// Register your graph-resource as usual.
manager->registerResource<ExampleResource>();
}
void registerTo(const smtk::view::Manager::Ptr& manager)
{
// This tuple list pairs of node+arc type.
// For the given node type, the given arc
// is requested and any destination nodes
// are listed as children:
using ExampleArcTraits = std::tuple<
std::pair<NodeTypeA, ArcTypeA>,
std::pair<NodeTypeA, ArcTypeB>,
std::pair<NodeTypeB, ArcTypeA>,
std::pair<NodeTypeC, ArcTypeC>
>;
// Note the traits and resource type are both passed to the
// graph subphrase-generator so it can verify that the node and
// arc classes belong to the resource in question.
manager->subphraseGeneratorFactory().registerType<
GraphSubphraseGenerator<ExampleArcTraits, ExampleResource>();
}
};
Once registered, any qtResourceBrowser instance can override the default configuration (in smtk/extension/qt/ResourcePanelConfiguration.json) and name the custom subphrase generator by type (see smtk/common/TypeName.h for details on how the name is computed).
If you need a tree with nodes from multiple graph resources, then either
- you would have to create a subphrase generator that used methods from 2 or more specialized GraphSubphraseGenerator<> instances; or
- SMTK would need to make GraphSubphraseGenerator accept multiple arc-traits and resource types.